soc.experiment package¶
Submodules¶
soc.experiment.alu_fsm module¶
Simple example of a FSM-based ALU
This demonstrates a design that follows the valid/ready protocol of the ALU, but with a FSM implementation, instead of a pipeline. It is also intended to comply with both the CompALU API and the nmutil Pipeline API (Liskov Substitution Principle)
The basic rules are:
- p.ready_o is asserted on the initial (“Idle”) state, otherwise it keeps low.
- n.valid_o is asserted on the final (“Done”) state, otherwise it keeps low.
- The FSM stays in the Idle state while p.valid_i is low, otherwise it accepts the input data and moves on.
- The FSM stays in the Done state while n.ready_i is low, otherwise it releases the output data and goes back to the Idle state.
-
class
soc.experiment.alu_fsm.CompFSMOpSubset(name=None)¶
-
class
soc.experiment.alu_fsm.Shifter(width)¶ Bases:
nmigen.hdl.ir.ElaboratableSimple sequential shifter
Prev port data: * p.data_i.data: value to be shifted * p.data_i.shift: shift amount * When zero, no shift occurs. * On POWER, range is 0 to 63 for 32-bit, * and 0 to 127 for 64-bit. * Other values wrap around.
Operation type * op.sdir: shift direction (0 = left, 1 = right)
Next port data: * n.data_o.data: shifted value
-
elaborate(platform)¶
-
ports()¶
-
-
soc.experiment.alu_fsm.test_shifter()¶
soc.experiment.alu_hier module¶
Experimental ALU: based on nmigen alu_hier.py, includes branch-compare ALU
This ALU is deliberately designed to add in (unnecessary) delays into different operations so as to be able to test the 6600-style matrices and the CompUnits. Countdown timers wait for (defined) periods before indicating that the output is valid
A “real” integer ALU would place the answers onto the output bus after only one cycle (sync)
-
class
soc.experiment.alu_hier.ALU(width)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
ports()¶
-
-
class
soc.experiment.alu_hier.BranchALU(width)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
ports()¶
-
-
class
soc.experiment.alu_hier.BranchOp(width, op)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
-
class
soc.experiment.alu_hier.DummyALU(width)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
ports()¶
-
-
class
soc.experiment.alu_hier.Multiplier(width)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
-
class
soc.experiment.alu_hier.Shifter(width)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
-
class
soc.experiment.alu_hier.SignExtend(width)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
-
class
soc.experiment.alu_hier.Subtractor(width)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
-
soc.experiment.alu_hier.alu_sim(dut)¶
-
soc.experiment.alu_hier.run_op(dut, a, b, op, inv_a=0)¶
-
soc.experiment.alu_hier.test_alu()¶
-
soc.experiment.alu_hier.test_alu_parallel()¶
-
soc.experiment.alu_hier.write_alu_gtkw(gtkw_name, clk_period=1e-06, sub_module=None, pysim=True)¶ Common function to write the GTKWave documents for this module
soc.experiment.cache_ram module¶
soc.experiment.compalu module¶
-
class
soc.experiment.compalu.ComputationUnitNoDelay(rwid, alu)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
ports()¶
-
-
soc.experiment.compalu.op_sim(dut, a, b, op, inv_a=0, imm=0, imm_ok=0)¶
-
soc.experiment.compalu.scoreboard_sim(dut)¶
-
soc.experiment.compalu.test_scoreboard()¶
soc.experiment.compalu_multi module¶
Computation Unit (aka “ALU Manager”).
Manages a Pipeline or FSM, ensuring that the start and end time are 100% monitored. At no time may the ALU proceed without this module notifying the Dependency Matrices. At no time is a result production “abandoned”. This module blocks (indicates busy) starting from when it first receives an opcode until it receives notification that its result(s) have been successfully stored in the regfile(s)
Documented at http://libre-soc.org/3d_gpu/architecture/compunit
-
class
soc.experiment.compalu_multi.CompUnitRecord(subkls, rwid, n_src=None, n_dst=None, name=None)¶ Bases:
soc.fu.regspec.RegSpec,nmutil.iocontrol.RecordObjectbase class for Computation Units, to provide a uniform API and allow “record.connect” etc. to be used, particularly when it comes to connecting multiple Computation Units up as a block (very laborious)
LDSTCompUnitRecord should derive from this class and add the additional signals it requires
Subkls: the class (not an instance) needed to construct the opcode Rwid: either an integer (specifies width of all regs) or a “regspec” see https://libre-soc.org/3d_gpu/architecture/regfile/ section on regspecs
-
class
soc.experiment.compalu_multi.MultiCompUnit(rwid, alu, opsubsetkls, n_src=2, n_dst=1, name=None)¶ Bases:
soc.fu.regspec.RegSpecALUAPI,nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
get_fu_out(i)¶
-
ports()¶
-
-
soc.experiment.compalu_multi.find_ok(fields)¶ find_ok helper function - finds field ending in “_ok”
-
soc.experiment.compalu_multi.go_record(n, name)¶
soc.experiment.compldst_multi module¶
LOAD / STORE Computation Unit.
This module covers POWER9-compliant Load and Store operations, with selection on each between immediate and indexed mode as options for the calculation of the Effective Address (EA), and also “update” mode which optionally stores that EA into an additional register.
take the time to review the links, video, and diagram.¶
Stores are activated when Go_Store is enabled, and use a sync’d “ADD” to compute the “Effective Address”, and, when ready the operand (src3_i) is stored in the computed address (passed through to the PortInterface)
Loads are activated when Go_Write[0] is enabled. The EA is computed, and (as long as there was no exception) the data comes out (at any time from the PortInterface), and is captured by the LDCompSTUnit.
Both LD and ST may request that the address be computed from summing operand1 (src[0]) with operand2 (src[1]) or by summing operand1 with the immediate (from the opcode).
Both LD and ST may also request “update” mode (op_is_update) which activates the use of Go_Write[1] to control storage of the EA into a second operand in the register file.
Thus this module has TWO write-requests to the register file and THREE read-requests to the register file (not all at the same time!) The regfile port usage is:
- LD-imm 1R1W
- LD-imm-update 1R2W
- LD-idx 2R1W
- LD-idx-update 2R2W
- ST-imm 2R
- ST-imm-update 2R1W
- ST-idx 3R
- ST-idx-update 3R1W
It’s a multi-level Finite State Machine that (unfortunately) nmigen.FSM is not suited to (nmigen.FSM is clock-driven, and some aspects of the nested FSMs below are combinatorial).
- One FSM covers Operand collection and communication address-side with the LD/ST PortInterface. its role ends when “RD_DONE” is asserted
- A second FSM activates to cover LD. it activates if op_is_ld is true
- A third FSM activates to cover ST. it activates if op_is_st is true
- The “overall” (fourth) FSM coordinates the progression and completion of the three other FSMs, firing “WR_RESET” which switches off “busy”
Full diagram:
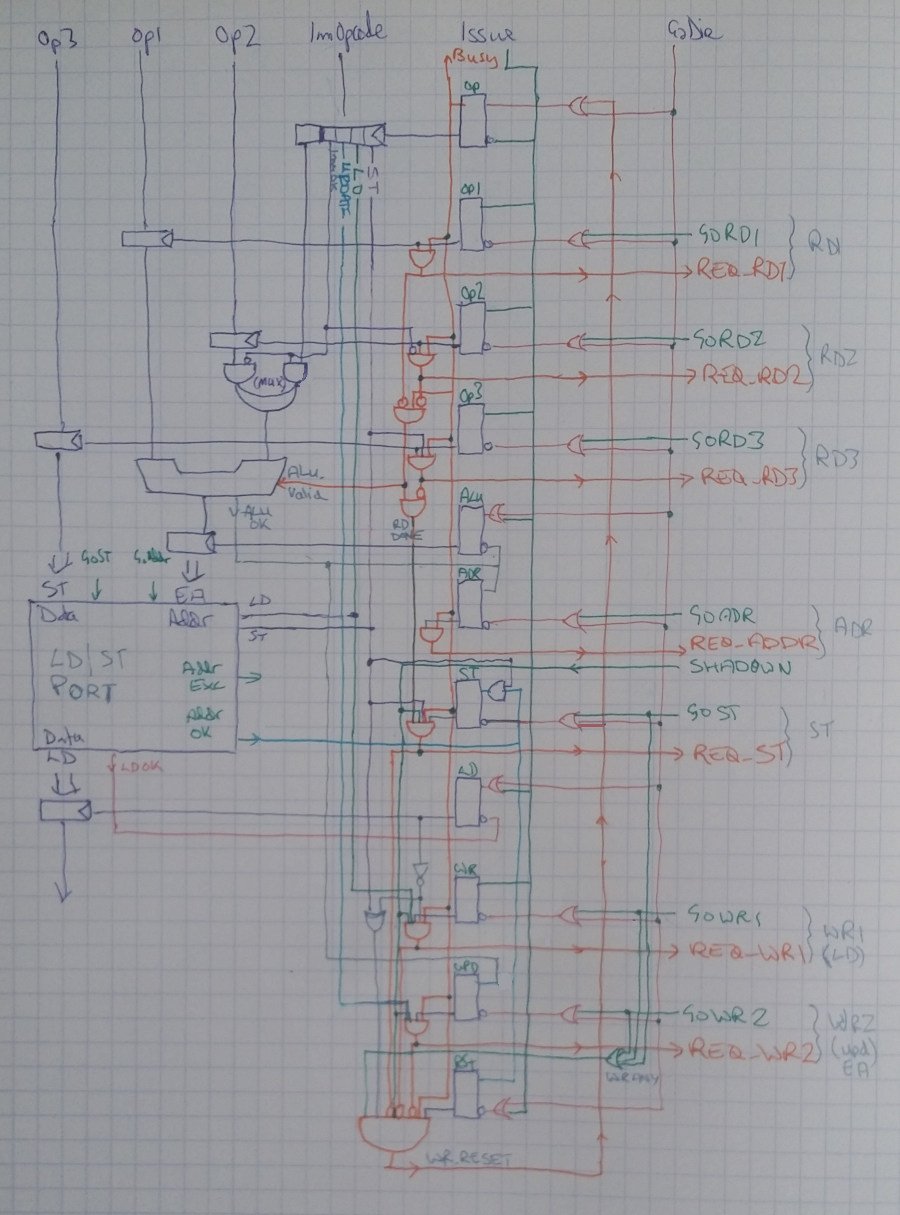{kind=link}
Links including to walk-through videos:
Related Bugreports:
Terminology:
- EA - Effective Address
- LD - Load
- ST - Store
-
class
soc.experiment.compldst_multi.LDSTCompUnit(pi=None, rwid=64, awid=48, opsubset=<class 'soc.fu.ldst.ldst_input_record.CompLDSTOpSubset'>, debugtest=False, name=None)¶ Bases:
soc.fu.regspec.RegSpecAPI,nmigen.hdl.ir.ElaboratableLOAD / STORE Computation Unit
pi: a PortInterface to the memory subsystem (read-write capable) rwid: register width awid: address width
src_i: Source Operands (RA/RB/RC) - managed by rd[0-3] go/req
data_o: Dest out (LD) - managed by wr[0] go/req addr_o: Address out (LD or ST) - managed by wr[1] go/req exception_o: Address/Data Exception occurred. LD/ST must terminate
- TODO: make exception_o a data-type rather than a single-bit signal
- (see bug #302)
oper_i: operation being carried out (POWER9 decode LD/ST subset) issue_i: LD/ST is being “issued”. shadown_i: Inverted-shadow is being held (stops STORE and WRITE) go_rd_i: read is being actioned (latches in src regs) go_wr_i: write mode (exactly like ALU CompUnit) go_ad_i: address is being actioned (triggers actual mem LD) go_st_i: store is being actioned (triggers actual mem STORE) go_die_i: resets the unit back to “wait for issue”
busy_o: function unit is busy rd_rel_o: request src1/src2 adr_rel_o: request address (from mem) sto_rel_o: request store (to mem) req_rel_o: request write (result) load_mem_o: activate memory LOAD stwd_mem_o: activate memory STORE
Note: load_mem_o, stwd_mem_o and req_rel_o MUST all be acknowledged in a single cycle and the CompUnit set back to doing another op. This means deasserting go_st_i, go_ad_i or go_wr_i as appropriate depending on whether the operation is a ST or LD.
Note: LDSTCompUnit takes care of LE/BE normalisation: * LD data is normalised after receipt from the PortInterface * ST data is normalised prior to sending onto the PortInterface TODO: use one module for the byte-reverse as it’s quite expensive in gates
-
elaborate(platform)¶
-
get_fu_out(i)¶
-
get_out(i)¶ make LDSTCompUnit look like RegSpecALUAPI
-
ports()¶
-
class
soc.experiment.compldst_multi.LDSTCompUnitRecord(rwid, opsubset=<class 'soc.fu.ldst.ldst_input_record.CompLDSTOpSubset'>, name=None)¶
-
class
soc.experiment.compldst_multi.TestLDSTCompUnit(rwid)¶ Bases:
soc.experiment.compldst_multi.LDSTCompUnit-
elaborate(platform)¶
-
-
class
soc.experiment.compldst_multi.TestLDSTCompUnitRegSpec¶ Bases:
soc.experiment.compldst_multi.LDSTCompUnit-
elaborate(platform)¶
-
-
soc.experiment.compldst_multi.ldst_sim(dut)¶
-
soc.experiment.compldst_multi.load(dut, src1, src2, imm, imm_ok=True, update=False, zero_a=False, byterev=True)¶
-
soc.experiment.compldst_multi.store(dut, src1, src2, src3, imm, imm_ok=True, update=False, byterev=True)¶
-
soc.experiment.compldst_multi.test_scoreboard()¶
-
soc.experiment.compldst_multi.test_scoreboard_regspec()¶
-
soc.experiment.compldst_multi.wait_for(sig, wait=True, test1st=False)¶
soc.experiment.cscore module¶
soc.experiment.cxxsim module¶
soc.experiment.dcache module¶
DCache
based on Anton Blanchard microwatt dcache.vhdl
-
soc.experiment.dcache.CacheRamOut()¶
-
soc.experiment.dcache.CacheTagArray()¶
-
soc.experiment.dcache.CacheValidBitsArray()¶
-
class
soc.experiment.dcache.DCache¶ Bases:
nmigen.hdl.ir.ElaboratableSet associative dcache write-through TODO (in no specific order): * See list in icache.vhdl * Complete load misses on the cycle when WB data comes instead of
at the end of line (this requires dealing with requests coming in while not idle…)-
cache_tag_read(m, r0_stall, req_index, cache_tag_set, cache_tags)¶ Cache tag RAM read port
-
dcache_fast_hit(m, req_op, r0_valid, r0, r1, req_hit_way, req_index, req_tag, access_ok, tlb_hit, tlb_hit_way, tlb_req_index)¶
-
dcache_log(m, r1, valid_ra, tlb_hit_way, stall_out)¶
-
dcache_request(m, r0, ra, req_index, req_row, req_tag, r0_valid, r1, cache_valids, replace_way, use_forward1_next, use_forward2_next, req_hit_way, plru_victim, rc_ok, perm_attr, valid_ra, perm_ok, access_ok, req_op, req_go, tlb_pte_way, tlb_hit, tlb_hit_way, tlb_valid_way, cache_tag_set, cancel_store, req_same_tag, r0_stall, early_req_row)¶ Cache request parsing and hit detection
-
dcache_slow(m, r1, use_forward1_next, use_forward2_next, cache_valids, r0, replace_way, req_hit_way, req_same_tag, r0_valid, req_op, cache_tags, req_go, ra)¶
-
elaborate(platform)¶
-
maybe_plrus(m, r1, plru_victim)¶ Generate PLRUs
-
maybe_tlb_plrus(m, r1, tlb_plru_victim)¶ Generate TLB PLRUs
-
rams(m, r1, early_req_row, cache_out_row, replace_way)¶ Generate a cache RAM for each way. This handles the normal reads, writes from reloads and the special store-hit update path as well.
Note: the BRAMs have an extra read buffer, meaning the output is pipelined an extra cycle. This differs from the icache. The writeback logic needs to take that into account by using 1-cycle delayed signals for load hits.
-
reservation_comb(m, cancel_store, set_rsrv, clear_rsrv, r0_valid, r0, reservation)¶ Handle load-with-reservation and store-conditional instructions
-
reservation_reg(m, r0_valid, access_ok, set_rsrv, clear_rsrv, reservation, r0)¶
-
stage_0(m, r0, r1, r0_full)¶ Latch the request in r0.req as long as we’re not stalling
-
tlb_read(m, r0_stall, tlb_valid_way, tlb_tag_way, tlb_pte_way, dtlb_valid_bits, dtlb_tags, dtlb_ptes)¶ TLB Operates in the second cycle on the request latched in r0.req. TLB updates write the entry at the end of the second cycle.
-
tlb_search(m, tlb_req_index, r0, r0_valid, tlb_valid_way, tlb_tag_way, tlb_hit_way, tlb_pte_way, pte, tlb_hit, valid_ra, perm_attr, ra)¶
-
tlb_update(m, r0_valid, r0, dtlb_valid_bits, tlb_req_index, tlb_hit_way, tlb_hit, tlb_plru_victim, tlb_tag_way, dtlb_tags, tlb_pte_way, dtlb_ptes)¶
-
writeback_control(m, r1, cache_out_row)¶ Return data for loads & completion control logic
-
-
class
soc.experiment.dcache.DCachePendingHit(tlb_pte_way, tlb_valid_way, tlb_hit_way, cache_valid_idx, cache_tag_set, req_addr, hit_set)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
-
soc.experiment.dcache.HitWaySet()¶
-
class
soc.experiment.dcache.MemAccessRequest(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
class
soc.experiment.dcache.Op¶ Bases:
enum.EnumAn enumeration.
-
OP_BAD= 1¶
-
OP_LOAD_HIT= 3¶
-
OP_LOAD_MISS= 4¶
-
OP_LOAD_NC= 5¶
-
OP_NONE= 0¶
-
OP_STCX_FAIL= 2¶
-
OP_STORE_HIT= 6¶
-
OP_STORE_MISS= 7¶
-
-
soc.experiment.dcache.PLRUOut()¶
-
class
soc.experiment.dcache.PermAttr(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
class
soc.experiment.dcache.RegStage0(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
class
soc.experiment.dcache.RegStage1(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
class
soc.experiment.dcache.Reservation¶ Bases:
nmutil.iocontrol.RecordObject
-
soc.experiment.dcache.RowPerLineValidArray()¶
-
class
soc.experiment.dcache.State¶ Bases:
enum.EnumAn enumeration.
-
IDLE= 0¶
-
NC_LOAD_WAIT_ACK= 3¶
-
RELOAD_WAIT_ACK= 1¶
-
STORE_WAIT_ACK= 2¶
-
-
soc.experiment.dcache.TLBPLRUOut()¶
-
soc.experiment.dcache.TLBPtesArray()¶
-
soc.experiment.dcache.TLBTagEAArray()¶
-
soc.experiment.dcache.TLBTagsArray()¶
-
soc.experiment.dcache.TLBValidBitsArray()¶
-
soc.experiment.dcache.dcache_load(dut, addr, nc=0)¶
-
soc.experiment.dcache.dcache_random_sim(dut)¶
-
soc.experiment.dcache.dcache_sim(dut)¶
-
soc.experiment.dcache.dcache_store(dut, addr, data, nc=0)¶
-
soc.experiment.dcache.extract_perm_attr(pte)¶
-
soc.experiment.dcache.get_index(addr)¶
-
soc.experiment.dcache.get_row(addr)¶
-
soc.experiment.dcache.get_row_of_line(row)¶
-
soc.experiment.dcache.get_tag(addr)¶
-
soc.experiment.dcache.is_last_row(row, last)¶
-
soc.experiment.dcache.is_last_row_addr(addr, last)¶
-
soc.experiment.dcache.ispow2(x)¶
-
soc.experiment.dcache.next_row(row)¶
-
soc.experiment.dcache.read_tag(way, tagset)¶
-
soc.experiment.dcache.read_tlb_pte(way, ptes)¶
-
soc.experiment.dcache.read_tlb_tag(way, tags)¶
-
soc.experiment.dcache.test_dcache(mem, test_fn, test_name)¶
-
soc.experiment.dcache.write_tlb_pte(way, ptes, newpte)¶
-
soc.experiment.dcache.write_tlb_tag(way, tags, tag)¶
soc.experiment.icache module¶
ICache
based on Anton Blanchard microwatt icache.vhdl
Set associative icache
TODO (in no specific order): * Add debug interface to inspect cache content * Add snoop/invalidate path * Add multi-hit error detection * Pipelined bus interface (wb or axi) * Maybe add parity? There’s a few bits free in each BRAM row on Xilinx * Add optimization: service hits on partially loaded lines * Add optimization: (maybe) interrupt reload on fluch/redirect * Check if playing with the geometry of the cache tags allow for more
efficient use of distributed RAM and less logic/muxes. Currently we write TAG_BITS width which may not match full ram blocks and might cause muxes to be inferred for “partial writes”.
- Check if making the read size of PLRU a ROM helps utilization
-
soc.experiment.icache.CacheRamOut()¶
-
soc.experiment.icache.CacheTagArray()¶
-
soc.experiment.icache.CacheValidBitsArray()¶
-
class
soc.experiment.icache.ICache¶ Bases:
nmigen.hdl.ir.Elaboratable64 bit direct mapped icache. All instructions are 4B aligned.
-
elaborate(platform)¶
-
icache_comb(m, use_previous, r, req_index, req_row, req_hit_way, req_tag, real_addr, req_laddr, cache_valid_bits, cache_tags, access_ok, req_is_hit, req_is_miss, replace_way, plru_victim, cache_out_row)¶
-
icache_hit(m, use_previous, r, req_is_hit, req_hit_way, req_index, req_tag, real_addr)¶
-
icache_log(m, req_hit_way, ra_valid, access_ok, req_is_miss, req_is_hit, lway, wstate, r)¶
-
icache_miss(m, cache_valid_bits, r, req_is_miss, req_index, req_laddr, req_tag, replace_way, cache_tags, access_ok, real_addr)¶
-
icache_miss_clr_tag(m, r, replace_way, cache_valid_bits, req_index, tagset, cache_tags)¶
-
icache_miss_idle(m, r, req_is_miss, req_laddr, req_index, req_tag, replace_way, real_addr)¶
-
icache_miss_wait_ack(m, r, replace_way, inval_in, stbs_done, cache_valid_bits)¶
-
itlb_lookup(m, tlb_req_index, itlb_ptes, itlb_tags, real_addr, itlb_valid_bits, ra_valid, eaa_priv, priv_fault, access_ok)¶
-
itlb_update(m, itlb_valid_bits, itlb_tags, itlb_ptes)¶
-
maybe_plrus(m, r, plru_victim)¶
-
rams(m, r, cache_out_row, use_previous, replace_way, req_row)¶
-
-
soc.experiment.icache.PLRUOut()¶
-
class
soc.experiment.icache.RegInternal¶ Bases:
nmutil.iocontrol.RecordObject
-
soc.experiment.icache.RowPerLineValidArray()¶
-
class
soc.experiment.icache.State¶ Bases:
enum.EnumAn enumeration.
-
CLR_TAG= 1¶
-
IDLE= 0¶
-
WAIT_ACK= 2¶
-
-
soc.experiment.icache.TLBPtesArray()¶
-
soc.experiment.icache.TLBTagArray()¶
-
soc.experiment.icache.TLBValidBitsArray()¶
-
soc.experiment.icache.get_index(addr)¶
-
soc.experiment.icache.get_row(addr)¶
-
soc.experiment.icache.get_row_of_line(row)¶
-
soc.experiment.icache.get_tag(addr)¶
-
soc.experiment.icache.hash_ea(addr)¶
-
soc.experiment.icache.icache_sim(dut)¶
-
soc.experiment.icache.is_last_row(row, last)¶
-
soc.experiment.icache.is_last_row_addr(addr, last)¶
-
soc.experiment.icache.ispow2(n)¶
-
soc.experiment.icache.next_row(row)¶
-
soc.experiment.icache.read_insn_word(addr, data)¶
-
soc.experiment.icache.read_tag(way, tagset)¶
-
soc.experiment.icache.test_icache(mem)¶
-
soc.experiment.icache.write_tag(way, tagset, tag)¶
soc.experiment.imem module¶
-
class
soc.experiment.imem.TestMemFetchUnit(pspec)¶ Bases:
soc.minerva.units.fetch.FetchUnitInterface,nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
ports()¶
-
soc.experiment.l0_cache module¶
L0 Cache/Buffer
This first version is intended for prototyping and test purposes: it has “direct” access to Memory.
The intention is that this version remains an integral part of the test infrastructure, and, just as with minerva’s memory arrangement, a dynamic runtime config selects alternative memory arrangements rather than replaces and discards this code.
Links:
- https://bugs.libre-soc.org/show_bug.cgi?id=216
- https://libre-soc.org/3d_gpu/architecture/memory_and_cache/
-
class
soc.experiment.l0_cache.CacheRecord(name=None)¶ Bases:
nmigen.hdl.rec.Record
-
class
soc.experiment.l0_cache.DataMerger(array_size)¶ Bases:
nmigen.hdl.ir.ElaboratableMerges data based on an address-match matrix. Identifies (picks) one (any) row, then uses that row, based on matching address bits, to merge (OR) all data rows into the output.
Basically, by the time DataMerger is used, all of its incoming data is determined not to conflict. The last step before actually submitting the request to the Memory Subsystem is to work out which requests, on the same 128-bit cache line, can be “merged” due to them being: (A) on the same address (bits 4 and above) (B) having byte-enable lines that (as previously mentioned) do not conflict.
Therefore, put simply, this module will: (1) pick a row (any row) and identify it by an index labelled “idx” (2) merge all byte-enable lines which are on that same address, as
indicated by addr_match_i[idx], onto the output-
elaborate(platform)¶
-
-
class
soc.experiment.l0_cache.DataMergerRecord(name=None)¶ Bases:
nmigen.hdl.rec.Record{data: 128 bit, byte_enable: 16 bit}
-
class
soc.experiment.l0_cache.L0CacheBuffer(n_units, pimem, regwid=64, addrwid=48)¶ Bases:
nmigen.hdl.ir.ElaboratableL0 Cache / Buffer
Note that the final version will have two interfaces per LDSTCompUnit, to cover mis-aligned requests, as well as two 128-bit L1 Cache interfaces: one for odd (addr[4] == 1) and one for even (addr[4] == 1).
This version is to be used for test purposes (and actively maintained for such, rather than “replaced”)
There are much better ways to implement this. However it’s only a “demo” / “test” class, and one important aspect: it responds combinatorially, where a nmigen FSM’s state-changes only activate on clock-sync boundaries.
Note: the data byte-order is not expected to be normalised (LE/BE) by this class. That task is taken care of by LDSTCompUnit.
-
elaborate(platform)¶
-
ports()¶
-
-
class
soc.experiment.l0_cache.L0CacheBuffer2(n_units=8, regwid=64, addrwid=48)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
-
class
soc.experiment.l0_cache.TestDataMerger(methodName='runTest')¶ Bases:
unittest.case.TestCase-
test_data_merger()¶
-
-
class
soc.experiment.l0_cache.TestDualPortSplitter(methodName='runTest')¶ Bases:
unittest.case.TestCase-
test_dual_port_splitter()¶
-
-
class
soc.experiment.l0_cache.TestL0Cache(methodName='runTest')¶ Bases:
unittest.case.TestCase-
test_l0_cache_test_bare_wb()¶
-
test_l0_cache_testpi()¶
-
-
class
soc.experiment.l0_cache.TstDataMerger2¶ Bases:
nmigen.hdl.ir.Elaboratable-
addr_match(j, addr)¶
-
elaborate(platform)¶
-
-
class
soc.experiment.l0_cache.TstL0CacheBuffer(pspec, n_units=3)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
ports()¶
-
-
soc.experiment.l0_cache.data_merger_merge(dut)¶
-
soc.experiment.l0_cache.data_merger_test2(dut)¶
-
soc.experiment.l0_cache.l0_cache_ld(dut, addr, datalen, expected)¶
-
soc.experiment.l0_cache.l0_cache_ldst(arg, dut)¶
-
soc.experiment.l0_cache.l0_cache_st(dut, addr, data, datalen)¶
-
soc.experiment.l0_cache.wait_addr(port)¶
-
soc.experiment.l0_cache.wait_busy(port, no=False)¶
-
soc.experiment.l0_cache.wait_ldok(port)¶
soc.experiment.lsmem module¶
-
class
soc.experiment.lsmem.TestMemLoadStoreUnit(pspec)¶ Bases:
soc.minerva.units.loadstore.LoadStoreUnitInterface,nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
soc.experiment.mem_types module¶
mem_types
based on Anton Blanchard microwatt common.vhdl
-
class
soc.experiment.mem_types.DCacheToLoadStore1Type(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
class
soc.experiment.mem_types.DCacheToMMUType(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
class
soc.experiment.mem_types.Fetch1ToICacheType(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
class
soc.experiment.mem_types.ICacheToDecode1Type(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
class
soc.experiment.mem_types.LoadStore1ToDCacheType(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
class
soc.experiment.mem_types.LoadStore1ToMMUType(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
class
soc.experiment.mem_types.MMUToDCacheType(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
class
soc.experiment.mem_types.MMUToICacheType(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
class
soc.experiment.mem_types.MMUToLoadStore1Type(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
soc.experiment.mmu module¶
MMU
based on Anton Blanchard microwatt mmu.vhdl
-
class
soc.experiment.mmu.MMU¶ Bases:
nmigen.hdl.ir.ElaboratableRadix MMU
Supports 4-level trees as in arch 3.0B, but not the two-step translation for guests under a hypervisor (i.e. there is no gRA -> hRA translation).
-
elaborate(platform)¶
-
mmu_0(m, r, rin, l_in, l_out, d_out, addrsh, mask)¶
-
proc_tbl_wait(m, v, r, data)¶
-
radix_read_wait(m, v, r, d_in, data)¶
-
radix_tree_idle(m, l_in, r, v)¶
-
segment_check(m, v, r, data, finalmask)¶
-
-
class
soc.experiment.mmu.RegStage(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
class
soc.experiment.mmu.State¶ Bases:
enum.EnumAn enumeration.
-
DO_TLBIE= 1¶
-
IDLE= 0¶
-
PROC_TBL_READ= 3¶
-
PROC_TBL_WAIT= 4¶
-
RADIX_FINISH= 9¶
-
RADIX_LOAD_TLB= 8¶
-
RADIX_LOOKUP= 6¶
-
RADIX_READ_WAIT= 7¶
-
SEGMENT_CHECK= 5¶
-
TLB_WAIT= 2¶
-
-
soc.experiment.mmu.dcache_get(dut)¶ simulator process for getting memory load requests
-
soc.experiment.mmu.mmu_sim(dut)¶
-
soc.experiment.mmu.mmu_wait(dut)¶
-
soc.experiment.mmu.test_mmu()¶
soc.experiment.pi2ls module¶
PortInterface to LoadStoreUnitInterface adapter
PortInterface LoadStoreUnitInterface ————- ———————-
is_ld_i/1 x_ld_i is_st_i/1 x_st_i
data_len/4 x_mask/16 (translate using LenExpand)
busy_o/1 most likely to be x_busy_o go_die_i/1 rst? addr.data/48 x_addr_i (x_addr_i[:4] goes into LenExpand) addr.ok/1 probably x_valid_i & ~x_stall_i
addr_ok_o/1 no equivalent. might work using x_stall_i exception_o/2(?) m_load_err_o and m_store_err_o
ld.data/64 m_ld_data_o ld.ok/1 probably implicit, when x_busy drops low st.data/64 x_st_data_i st.ok/1 probably kinda redundant, set to x_st_i
soc.experiment.pimem module¶
L0 Cache/Buffer
This first version is intended for prototyping and test purposes: it has “direct” access to Memory.
The intention is that this version remains an integral part of the test infrastructure, and, just as with minerva’s memory arrangement, a dynamic runtime config selects alternative memory arrangements rather than replaces and discards this code.
Links:
- https://bugs.libre-soc.org/show_bug.cgi?id=216
- https://libre-soc.org/3d_gpu/architecture/memory_and_cache/
-
class
soc.experiment.pimem.PortInterface(name=None, regwid=64, addrwid=48)¶ Bases:
nmutil.iocontrol.RecordObjectdefines the interface - the API - that the LDSTCompUnit connects to. note that this is NOT a “fire-and-forget” interface. the LDSTCompUnit must be kept appraised that the request is in progress, and only when it has a 100% successful completion can the notification be given (busy dropped).
The interface FSM rules are as follows:
if busy_o is asserted, a LD/ST is in progress. further requests may not be made until busy_o is deasserted.
only one of is_ld_i or is_st_i may be asserted. busy_o will immediately be asserted and remain asserted.
addr.ok is to be asserted when the LD/ST address is known. addr.data is to be valid on the same cycle.
addr.ok and addr.data must REMAIN asserted until busy_o is de-asserted. this ensures that there is no need for the L0 Cache/Buffer to have an additional address latch (because the LDSTCompUnit already has it)
addr_ok_o (or exception.happened) must be waited for. these will be asserted only for one cycle and one cycle only.
exception.happened will be asserted if there is no chance that the memory request may be fulfilled.
busy_o is deasserted on the same cycle as exception.happened is asserted.
conversely: addr_ok_o must ONLY be asserted if there is a HUNDRED PERCENT guarantee that the memory request will be fulfilled.
for a LD, ld.ok will be asserted - for only one clock cycle - at any point in the future that is acceptable to the underlying Memory subsystem. the recipient MUST latch ld.data on that cycle.
busy_o is deasserted on the same cycle as ld.ok is asserted.
for a ST, st.ok may be asserted only after addr_ok_o had been asserted, alongside valid st.data at the same time. st.ok must only be asserted for one cycle.
the underlying Memory is REQUIRED to pick up that data and guarantee its delivery. no back-acknowledgement is required.
busy_o is deasserted on the cycle AFTER st.ok is asserted.
-
connect_port(inport)¶
-
class
soc.experiment.pimem.PortInterfaceBase(regwid=64, addrwid=4)¶ Bases:
nmigen.hdl.ir.ElaboratableBase class for PortInterface-compliant Memory read/writers
-
addrbits¶
-
connect_port(inport)¶
-
elaborate(platform)¶
-
get_rd_data(m)¶
-
ports()¶
-
set_rd_addr(m, addr, mask)¶
-
set_wr_addr(m, addr, mask)¶
-
set_wr_data(m, data, wen)¶
-
splitaddr(addr)¶ split the address into top and bottom bits of the memory granularity
-
-
class
soc.experiment.pimem.TestMemoryPortInterface(regwid=64, addrwid=4)¶ Bases:
soc.experiment.pimem.PortInterfaceBaseThis is a test class for simple verification of the LDSTCompUnit and for the simple core, to be able to run unit tests rapidly and with less other code in the way.
Versions of this which are compatible (conform with PortInterface) will include augmented-Wishbone Bus versions, including ones that connect to L1, L2, MMU etc. etc. however this is the “base lowest possible version that complies with PortInterface”.
-
elaborate(platform)¶
-
get_rd_data(m)¶
-
ports()¶
-
set_rd_addr(m, addr, mask)¶
-
set_wr_addr(m, addr, mask)¶
-
set_wr_data(m, data, wen)¶
-
soc.experiment.plru module¶
soc.experiment.score6600 module¶
-
class
soc.experiment.score6600.CompUnitALUs(rwid, opwid, n_alus)¶ Bases:
soc.experiment.score6600.CompUnitsBase-
elaborate(platform)¶
-
-
class
soc.experiment.score6600.CompUnitBR(rwid, opwid)¶ Bases:
soc.experiment.score6600.CompUnitsBase-
elaborate(platform)¶
-
-
class
soc.experiment.score6600.CompUnitLDSTs(rwid, opwid, n_ldsts, mem)¶ Bases:
soc.experiment.score6600.CompUnitsBase-
elaborate(platform)¶
-
-
class
soc.experiment.score6600.CompUnitsBase(rwid, units, ldstmode=False)¶ Bases:
nmigen.hdl.ir.ElaboratableComputation Unit Base class.
Amazingly, this class works recursively. It’s supposed to just look after some ALUs (that can handle the same operations), grouping them together, however it turns out that the same code can also group groups of Computation Units together as well.
Basically it was intended just to concatenate the ALU’s issue, go_rd etc. signals together, which start out as bits and become sequences. Turns out that the same trick works just as well on Computation Units!
So this class may be used recursively to present a top-level sequential concatenation of all the signals in and out of ALUs, whilst at the same time making it convenient to group ALUs together.
At the lower level, the intent is that groups of (identical) ALUs may be passed the same operation. Even beyond that, the intent is that that group of (identical) ALUs actually share the same pipeline and as such become a “Concurrent Computation Unit” as defined by Mitch Alsup (see section 11.4.9.3)
-
elaborate(platform)¶
-
-
class
soc.experiment.score6600.FunctionUnits(n_regs, n_int_alus)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
-
class
soc.experiment.score6600.IssueToScoreboard(qlen, n_in, n_out, rwid, opwid, n_regs)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
ports()¶
-
-
class
soc.experiment.score6600.Scoreboard(rwid, n_regs)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
ports()¶
-
-
soc.experiment.score6600.create_random_ops(dut, n_ops, shadowing=False, max_opnums=3)¶
-
soc.experiment.score6600.disable_issue(dut)¶
-
soc.experiment.score6600.instr_q(dut, op, funit, op_imm, imm, src1, src2, dest, branch_success, branch_fail)¶
-
soc.experiment.score6600.int_instr(dut, op, imm, src1, src2, dest, branch_success, branch_fail)¶
-
soc.experiment.score6600.power_instr_q(dut, pdecode2, ins, code)¶
-
soc.experiment.score6600.power_sim(m, dut, pdecode2, instruction, alusim)¶
-
soc.experiment.score6600.print_reg(dut, rnums)¶
-
soc.experiment.score6600.scoreboard_branch_sim(dut, alusim)¶
-
soc.experiment.score6600.scoreboard_sim(dut, alusim)¶
-
soc.experiment.score6600.test_scoreboard()¶
-
soc.experiment.score6600.wait_for_busy_clear(dut)¶
-
soc.experiment.score6600.wait_for_issue(dut, dut_issue)¶
soc.experiment.score6600_multi module¶
-
class
soc.experiment.score6600_multi.CompUnitALUs(rwid, opwid, n_alus)¶ Bases:
soc.experiment.score6600_multi.CompUnitsBase-
elaborate(platform)¶
-
-
class
soc.experiment.score6600_multi.CompUnitBR(rwid, opwid)¶ Bases:
soc.experiment.score6600_multi.CompUnitsBase-
elaborate(platform)¶
-
-
class
soc.experiment.score6600_multi.CompUnitLDSTs(rwid, opwid, n_ldsts, l0)¶ Bases:
soc.experiment.score6600_multi.CompUnitsBase-
elaborate(platform)¶
-
-
class
soc.experiment.score6600_multi.CompUnitsBase(rwid, units, ldstmode=False)¶ Bases:
nmigen.hdl.ir.ElaboratableComputation Unit Base class.
Amazingly, this class works recursively. It’s supposed to just look after some ALUs (that can handle the same operations), grouping them together, however it turns out that the same code can also group groups of Computation Units together as well.
Basically it was intended just to concatenate the ALU’s issue, go_rd etc. signals together, which start out as bits and become sequences. Turns out that the same trick works just as well on Computation Units!
So this class may be used recursively to present a top-level sequential concatenation of all the signals in and out of ALUs, whilst at the same time making it convenient to group ALUs together.
At the lower level, the intent is that groups of (identical) ALUs may be passed the same operation. Even beyond that, the intent is that that group of (identical) ALUs actually share the same pipeline and as such become a “Concurrent Computation Unit” as defined by Mitch Alsup (see section 11.4.9.3)
-
elaborate(platform)¶
-
-
class
soc.experiment.score6600_multi.FunctionUnits(n_reg, n_int_alus, n_src, n_dst)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
-
class
soc.experiment.score6600_multi.IssueToScoreboard(qlen, n_in, n_out, rwid, opwid, n_regs)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
ports()¶
-
-
class
soc.experiment.score6600_multi.Scoreboard(rwid, n_regs)¶ Bases:
nmigen.hdl.ir.Elaboratable-
elaborate(platform)¶
-
ports()¶
-
-
soc.experiment.score6600_multi.create_random_ops(dut, n_ops, shadowing=False, max_opnums=3)¶
-
soc.experiment.score6600_multi.disable_issue(dut)¶
-
soc.experiment.score6600_multi.instr_q(dut, op, funit, op_imm, imm, src1, src2, dest, branch_success, branch_fail)¶
-
soc.experiment.score6600_multi.int_instr(dut, op, imm, src1, src2, dest, branch_success, branch_fail)¶
-
soc.experiment.score6600_multi.power_instr_q(dut, pdecode2, ins, code)¶
-
soc.experiment.score6600_multi.power_sim(m, dut, pdecode2, instruction, alusim)¶
-
soc.experiment.score6600_multi.print_reg(dut, rnums)¶
-
soc.experiment.score6600_multi.scoreboard_branch_sim(dut, alusim)¶
-
soc.experiment.score6600_multi.scoreboard_sim(dut, alusim)¶
-
soc.experiment.score6600_multi.test_scoreboard()¶
-
soc.experiment.score6600_multi.wait_for_busy_clear(dut)¶
-
soc.experiment.score6600_multi.wait_for_issue(dut, dut_issue)¶
soc.experiment.sim module¶
soc.experiment.testmem module¶
soc.experiment.wb_types module¶
wb_types
based on Anton Blanchard microwatt wishbone_types.vhdl
-
soc.experiment.wb_types.WBAddrType()¶
-
soc.experiment.wb_types.WBDataType()¶
-
class
soc.experiment.wb_types.WBIOMasterOut(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
class
soc.experiment.wb_types.WBIOSlaveOut(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
soc.experiment.wb_types.WBIOSlaveOutInit()¶
-
class
soc.experiment.wb_types.WBMasterOut(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
soc.experiment.wb_types.WBMasterOutInit()¶
-
soc.experiment.wb_types.WBMasterOutVector()¶
-
soc.experiment.wb_types.WBSelType()¶
-
class
soc.experiment.wb_types.WBSlaveOut(name=None)¶ Bases:
nmutil.iocontrol.RecordObject
-
soc.experiment.wb_types.WBSlaveOutInit()¶
-
soc.experiment.wb_types.WBSlaveOutVector()¶